Predict
Predict is a functionality to make inferences on the input data using the Bayesian network. The inference on the dataset is performed sample-wise by using all the available nodes as evidence (obviously, with the exception of the node whose values we are predicting). The states with highest probability are then returned.
Lets create a small example to understand how it exactly works..
Predict example
# Import bnlearn
import bnlearn as bn
# Load example DataFrame
df = bn.import_example('asia')
# The dataframe consists four boolean variables
print(df)
# smoke lung bronc xray
# 0 0 1 0 1
# 1 0 1 1 1
# 2 1 1 1 1
# 3 1 1 0 1
# 4 1 1 1 1
# ... ... ... ...
# 9995 1 1 1 1
# 9996 1 1 1 1
# 9997 0 1 1 1
# 9998 0 1 1 1
# 9999 0 1 1 0
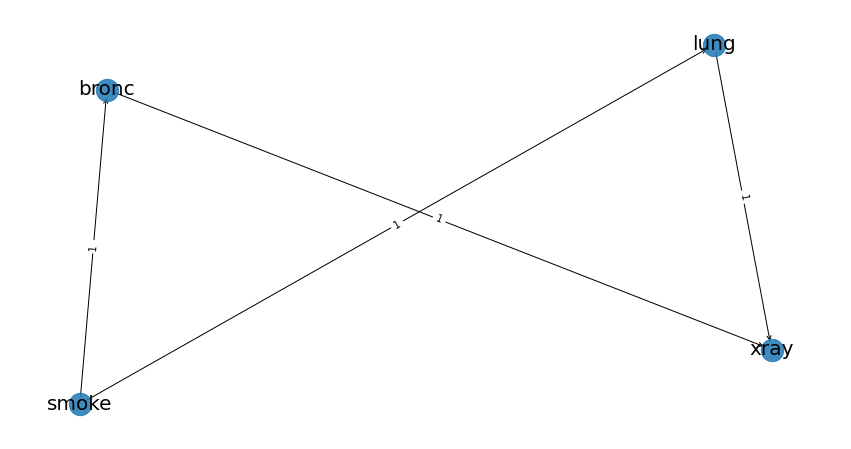
# Lets create a DAG by defining some edges between the variables. In this example smoke is related to lung, smoke to bronc, lung to xray and bronc to xray.
edges = [('smoke', 'lung'),
('smoke', 'bronc'),
('lung', 'xray'),
('bronc', 'xray')]
# With th edges, we can make a bayesian DAG by simply running the following line.
DAG = bn.make_DAG(edges, verbose=0)
# Plot DAG
bn.plot(DAG)
# With the bayesian DAG and the dataframe we can start learning the CPDs for each node
model = bn.parameter_learning.fit(DAG, df, verbose=3)
# bn.print_CPD(model)
# Lets create some data based on the learned model
Xtest = bn.sampling(model, n=1000)
print(Xtest)
# smoke lung bronc xray
# 0 1 1 1 1
# 1 1 1 1 1
# 2 0 1 1 1
# 3 1 0 0 1
# 4 1 1 1 1
# .. ... ... ... ...
# 995 1 1 1 1
# 996 1 1 1 1
# 997 0 1 0 1
# 998 0 1 0 1
# 999 0 1 1 1
# Without the predict function we can only make a single inference at the time (see below).
# To asses an entire dataframe, such as *Xtest*, it is a lot of work though.
query = bn.inference.fit(DAG, variables=['bronc','xray'], evidence={'smoke':1, 'lung':1}, verbose=3)
query.df
print(query)
+----------+---------+-------------------+
| bronc | xray | phi(bronc,xray) |
+==========+=========+===================+
| bronc(0) | xray(0) | 0.0296 |
+----------+---------+-------------------+
| bronc(0) | xray(1) | 0.2986 |
+----------+---------+-------------------+
| bronc(1) | xray(0) | 0.0517 |
+----------+---------+-------------------+
| bronc(1) | xray(1) | 0.6201 |
+----------+---------+-------------------+
# With the predict function we can now easily asses the entire dataframe for the specified input variables.
# In this case we are going to asses bronc and xray for the entire dataframe.
# The inference on the dataset is performed sample-wise by using all the available nodes as evidence (obviously, with the exception of the node whose values we are predicting).
# The states with highest probability are then returned.
Pout = bn.predict(model, Xtest, variables=['bronc','xray'])
print(Pout)
# bronc xray p
# 0 1 1 0.620068
# 1 1 1 0.620068
# 2 0 1 0.544772
# 3 1 0 0.488032
# 4 1 1 0.620068
# .. ... ... ...
# 995 1 1 0.620068
# 996 1 1 0.620068
# 997 0 1 0.544772
# 998 0 1 0.544772
# 999 0 1 0.544772
# The first line shows bronc=1, xray=1 with P=0.62. This is the same Probabilty and results as demonstrated by the single query.
# This line is returned as it had the maximum probability as you can see in the query.