Splitting the data set
For supervised machine learning tasks it is very important to split the data into separate parts to avoid overfitting when learning the model. Overfitting is when the model fits (or learns) on the data too well and then fails to reliably predict on (new) unseen data. The most common manner is to split data set is into a trainset, and an independent validationset. However, when we also perform hyperparameter tuning, such as in boosting algorithms, it also requires a testset. The model can now see the data, learn from the data, and finally we can describe the stability of the model. Thus for boosting algorithms we devide the data into three parts, namely: trainset, testset and validationset. Each set has a different role, and is explained below.
Train, test and validationset
The model sees and learns from the data. To ensure stability in the model and results, we devide the data set into three parts with different sizes, namely: train-set, test-set and validation-set. Each set has a different role, and is explained below.
- The Trainset
This is the part where the model sees and learns from the data. It consists typically 70% or 80% of the samples to determine the best fit (in a 5 fold-cross validation scheme) across the thousands of possible hyperparameters.
- The validation set
The remaining 30% or 20% of the samples in the data is kept independent, and used in the final stage to get an unbiased evaluation of the model fit. It is important to realize that this set can only be used once. Or in other words, if the model is further optimized after getting new insights on this validation set, you need another independent set to evaluate the final model performance.
- The testset
This set contains typically 20% of the samples of the trainingset, and is is used to evaluate the model performance for the specific set of hyperparameters that are used to fit the model during the learning proces. Note that the testset contains a fixed set of samples, and therefore we can compare the model performance across the models for which the fit is based on different hyperparameters.
With hgboost we will first determine the best model using the train and test sets. After evaluating all hyperparameters, and selection of the best model, we will test the reliability of the model performance on an independent and unseen data set.
The use of a validation set is optional but it is strongly encouraged to use it. When setting val_size=None in hgboost.hgboost.hgboost(), there are more samples included in the train/testset for parameter hyperoptimization. Note that val_size can also be set to very low percentages but keep in mind that it then also may lead in a poorly overtrained model. The use of the testset should always be larger then 0 hgboost.hgboost.hgboost().
Cross validation and hyperparameter tuning
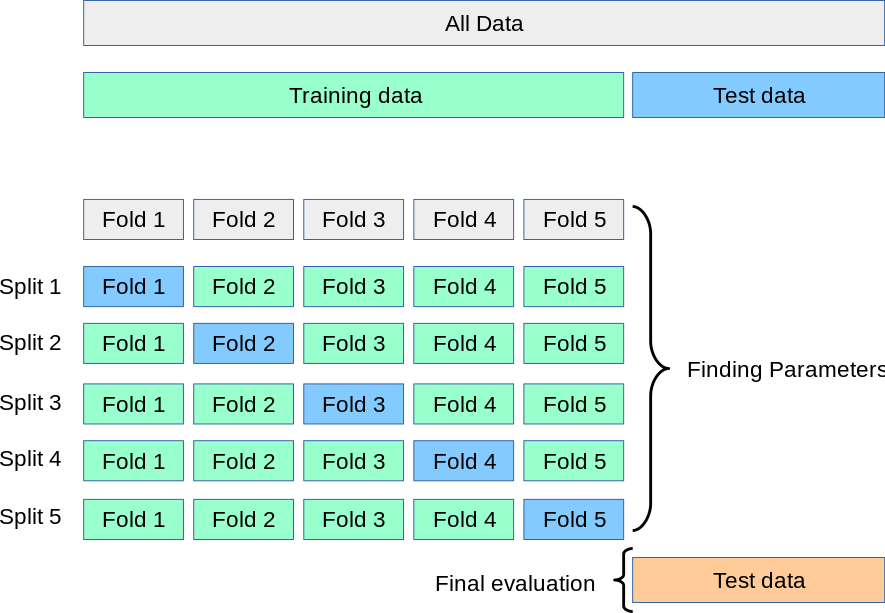
Cross validation and hyperparameter tuning are two tasks that we do together in the data pipeline. Cross validation is the process of training learners using one set of data and testing it using a different set. We set a default of 5-fold crossvalidation to evalute our results. Parameter tuning is the process of selecting the values for a model’s parameters that maximize the accuracy of the model.
Hyperparameter optimization
In hgboost we incorporated hyperparameter optimization using a hyperopt. The goal is to evaluate the value of the combination of parameters in the learning process.
We evaluate thousands of parameter combinations in the learning process. To ensure stability, the k-fold crossvalidation comes into play. To keep the computation costs low, we can decide to only cross-validate the top k detected models using the parameter top_cv_evals=10 in hgboost.hgboost.hgboost(). By default, we enable parallel processing. Each fit is scored based on the desired evaluation metric and the parameters of the best fit are used.
The specific list of parameter used for tuning are lised in section classification and regression.