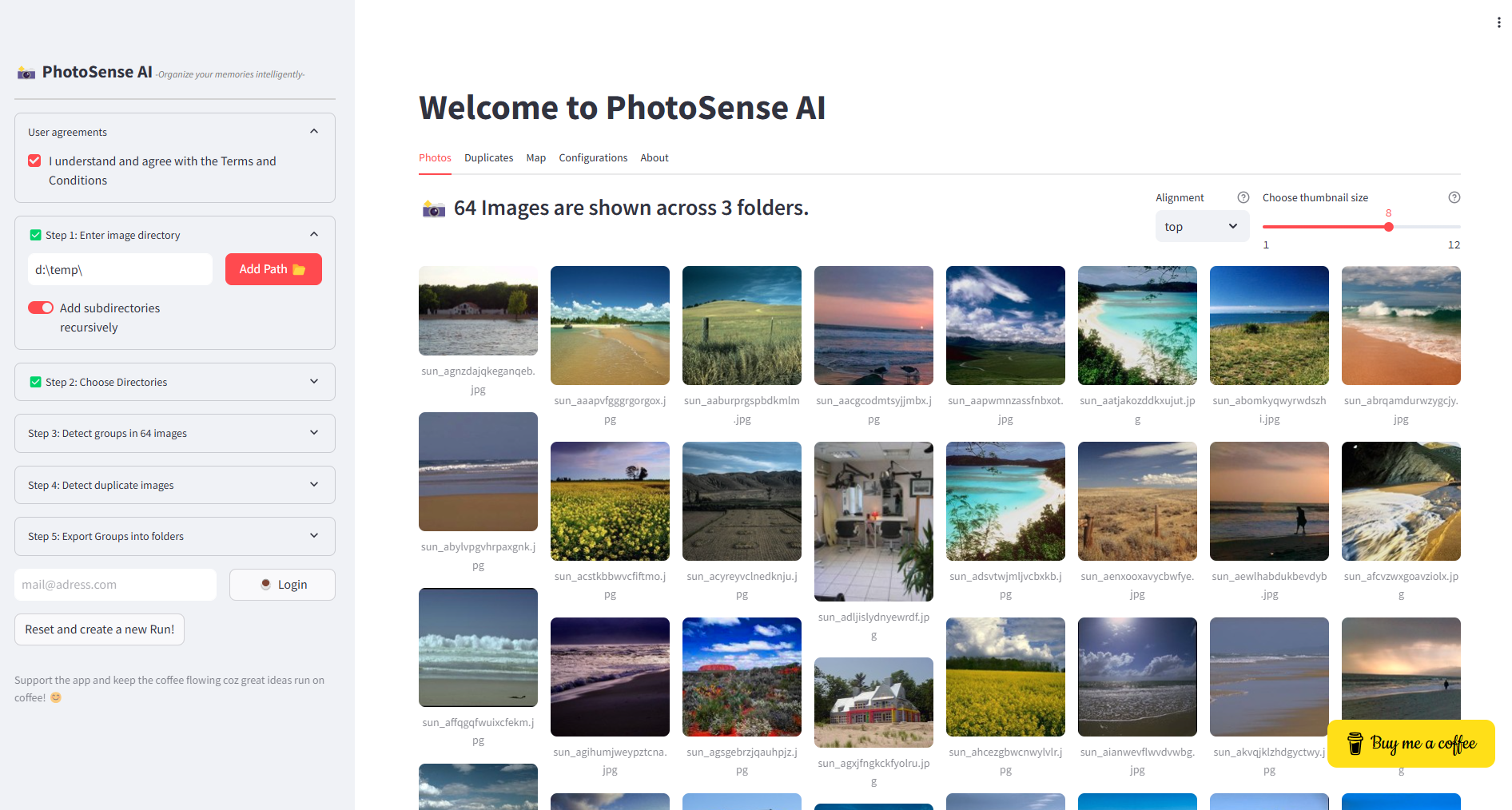
Scenes images (Medium dataset)
In this section, we will use toy datasets for demonstration purposes.
A small dataset containing three categories is the Scenes toy-example dataset This dataset contains a few hundred images over 3 categories which can be used to cluster based on the picture content.
|
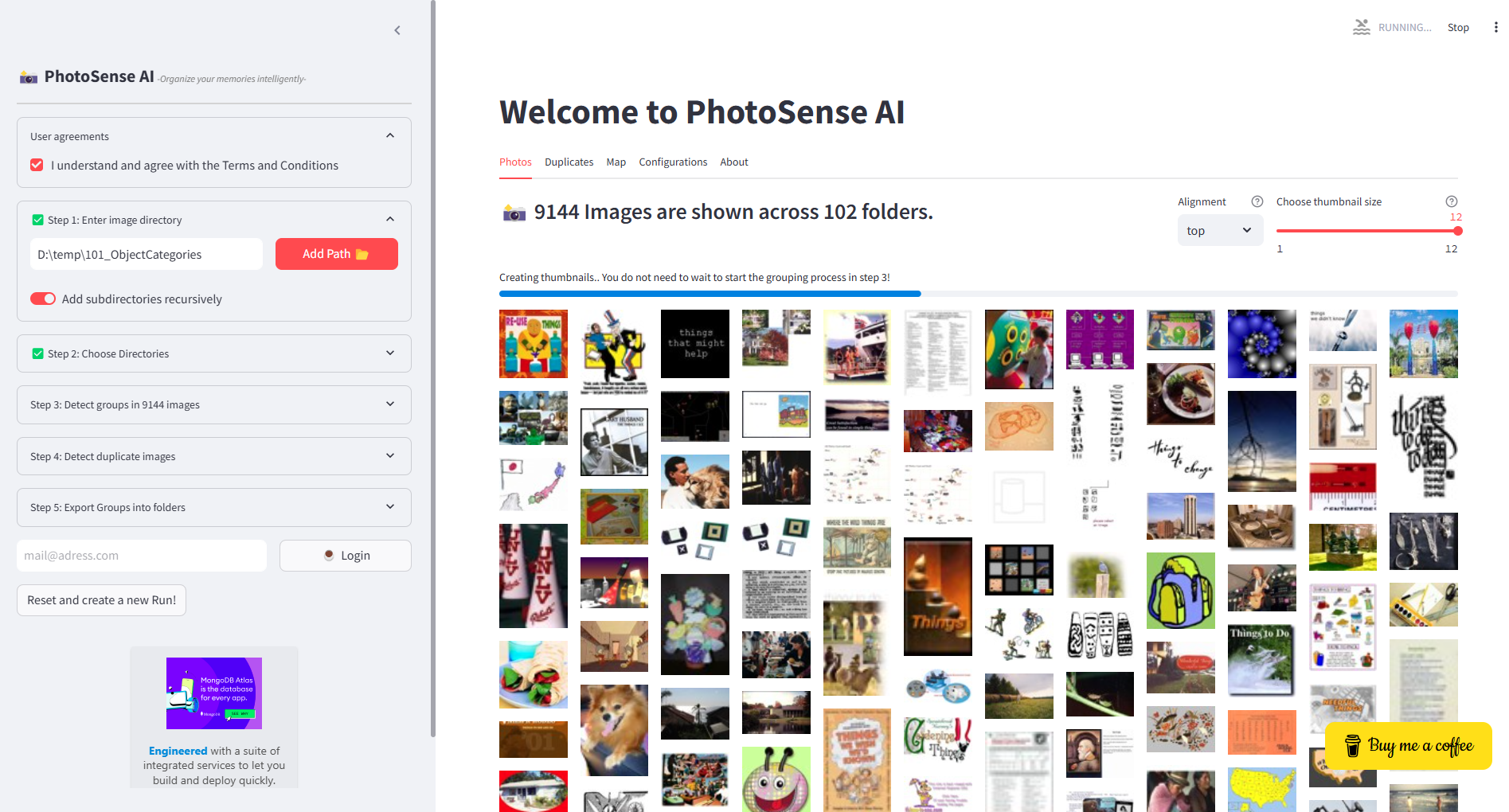
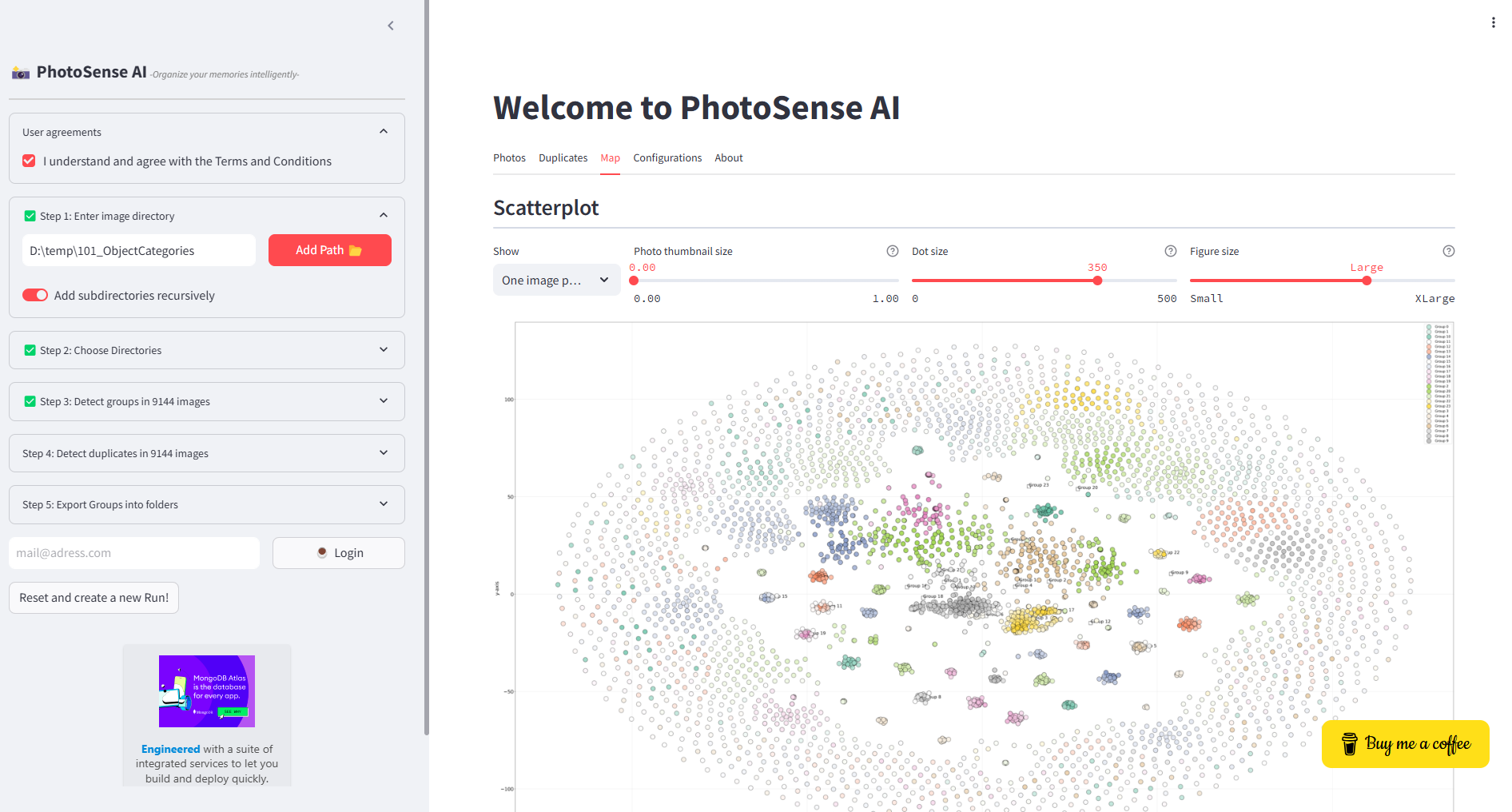
Caltech 101 (very large dataset)
A large dataset is the Caltech 101 objects dataset. The dataset contains 9,144 real-world images belonging to 101 categories. About 40 to 800 images per category. The size of each image is roughly 300 x 200 pixels and can be downloaded at the Caltech website. When we add the directory of the images to PhotoSense AI, all images in subdirectories will be recursively collected and processed.
Note
Read the blog Step by step guide to clustering images for more details.
On my machine (32GB internal memory), this amount of images is clearly the limit of what can be analyzed. One way to keep going is to lower the thumbnail resolution to 64 in the configurations to prevent out-of-memory issues. However, when doing so, the low-resolution images will have a negative impact on the accuracy of the clustering results. After waiting a couple of minutes, the thumbnails were loaded and could be clustered on Picture Content in Step 3.
|
|