Background
LLMlight is a lightweight library designed to simplify working with language models locally while providing powerful tools for retrieval-augmented workflows. Its core functionalities include chunking, embedding, context aggregation, statistical validation, and memory storage.
The goal of LLMlight is to enable both researchers and practitioners to quickly build and experiment with local language models without relying on cloud services. It provides: - Easy integration of local knowledge bases (FAISS, JSON, MemVid) - Reproducible training and retrieval pipelines - Tools for statistical validation to separate meaningful signals from noise - Visualization and plotting for better understanding of models and data
Output
Using LLMlight, users can efficiently: - Train and save local language models for specific tasks - Load saved models for inference or further training without retraining - Perform retrieval-augmented queries with statistical significance testing - Build applications such as chat-with-your-PDF, email auto-reply engines, or personal document assistants - Visualize embeddings, layer usage, and memory retrieval via plotting tools
Schematic Overview
The schematic overview of our approach is as follows:
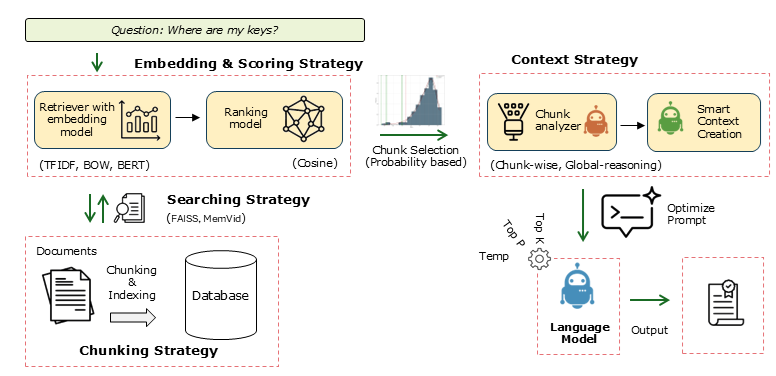
The figure illustrates the end-to-end workflow:
Input data or documents are preprocessed and chunked.
Chunks are embedded and optionally stored in a local database.
A language model uses the chunks and context aggregation strategies for inference.
Retrieval results are statistically validated via null distribution modeling.
Outputs can be visualized, saved, and reused in future sessions.