Algorithm
The LLMlight method consists of several key components: Preprocessing & Chunking, Embedding & Local Storage, and Retrieval-Augmented Generation with Statistical Validation. Each component contributes to efficient, accurate, and reproducible handling of user queries over large document collections.
The figure below illustrates the end-to-end workflow of LLMlight:
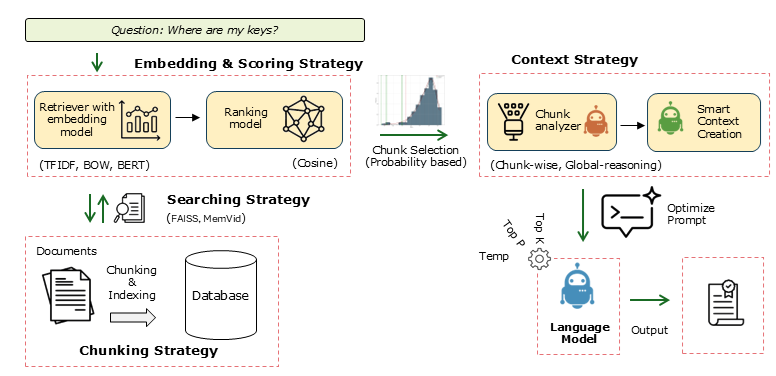
Schematic overview of the LLMlight workflow.
Workflow Steps
Input Data or Documents: Raw documents (PDFs, text files, etc.) are preprocessed to remove noise such as headers, footers, and boilerplate text.
Chunking: Documents are split into meaningful chunks to ensure each contains enough context for embedding and retrieval.
Embedding & Local Storage: Each chunk is transformed into vector embeddings and optionally stored in a local database (e.g., FAISS, MemVid) for offline, efficient, and portable retrieval.
Query Processing & Retrieval: User queries are transformed into embeddings and compared against the stored chunks using similarity measures.
Statistical Validation: LLMlight constructs a null distribution to assess the statistical significance of retrieved chunks, separating true signal from noise.
Context Aggregation & LLM Inference: Selected chunks are aggregated and provided as context to the local language model for generation of accurate and grounded responses.
Output & Visualization: Results can be saved, reused, or visualized using the built-in plotting tools.
Note
This schematic provides a clear picture of how LLMlight integrates preprocessing, embeddings, local storage, statistical validation, and language model inference into a robust retrieval-augmented generation system.
Get Available LLM Models
LLMlight allows users to query which language models are available locally or for download. This is useful when you want to quickly switch models, validate compatibility, or explore alternative options for your use case.
This method returns a list of model names that can be used in the LLMlight.LLMlight initializer for creating local language models.
Retrieving available models can be done via the LLMlight.LLMlight.LLMlight.get_available_models() method.
from LLMlight import LLMlight
# Initialize LLMlight client
client = LLMlight(verbose='info')
# Get a list of available models
modelnames = client.get_available_models(validate=False)
# Print available models
print("Available models:", modelnames)
validate=False: Skips checking the integrity or availability of models, making retrieval faster.
verbose=’info’: Shows additional information during model retrieval, such as download progress or caching messages.
Preprocessing & Chunking
The first step is Preprocessing & Chunking. Input documents are split into manageable chunks to allow efficient embedding and retrieval. Headers, footers, and boilerplate text are removed to reduce noise. Chunks are sized appropriately (typically >200 characters) to avoid hallucinations.
from LLMlight import LLMlight
# Initialize with default settings
client = LLMlight(model='mistralai/mistral-small-3.2', file_path='local_database.mp4')
# Example PDFs to process
url1 = 'https://proceedings.neurips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf'
url2 = 'https://erdogant.github.io/publications/papers/2020%20-%20Taskesen%20et%20al%20-%20HNet%20Hypergeometric%20Networks.pdf'
Embedding & Local Storage
In Embedding & Local Storage, each chunk is transformed into a vector representation. These embeddings are stored in local databases such as FAISS or MemVid, making retrieval fast, offline-friendly, and portable. Users can also add small text chunks or entire directories.
# Add multiple PDF files to the database
client.memory_add(files=[url1, url2])
# Add additional text chunks
client.memory_add(text=[
'Small chunk that is also added to the database.',
'The capital of France is Amsterdam.'
], overwrite=True)
# Add all supported file types from a directory
client.memory_add(
dirpath='c:/my_documents/',
filetypes=['.pdf', '.txt', '.epub', '.md', '.doc', '.docx', '.rtf', '.html', '.htm']
)
# Store the database to disk
client.memory_save()
RAG with Statistical Validation
During Retrieval-Augmented Generation (RAG), queries are compared against stored chunks using similarity measures. LLMlight constructs a null distribution of scores to evaluate statistical significance. Only chunks that are likely relevant are selected and aggregated for the language model to generate grounded responses.
# Load database for inference
client = LLMlight(model='mistralai/mistral-small-3.2', file_path='local_database.mp4')
# Inspect top 5 chunks
client.memory_chunks(n=5)
# Search through chunks using queries
out1 = client.memory.retriever.search('Attention Is All You Need', top_k=3)
out2 = client.memory.retriever.search('Enrichment analysis, Hypergeometric Networks', top_k=3)
out3 = client.memory.retriever.search('Capital of Amsterdam', top_k=3)
Note
This approach separates true signal from coincidental patterns, making retrieval robust and ensuring that responses are based on meaningful content rather than surface-level similarity.